

As I applied for a PhD position, I wanted to give the professor a reason to hire me, so I implemented one of my ideas. I suspected that the weight of neural networks are too dense. There is a lot of redundancy. The conventional way to reduce complexity is to have a funnel in the neural network architecture. However, this is an expensive way to tackle the problem. Instead of reducing the number of weights, we are increasing them. The other way to reduce the complexity of a model is by reducing the precision of the weights from, e.g., 32bit to 8bit. This is a legitimate way to handle the issue. However, it is one uninspired and two hard to believe that it is the only way and the correct way for all situations.
My hypothesis was to just compress the weight matrix with a common algorithm like JPEG. I took MNIST trained a small CNN:
hidden_layer_size = 512
linear1 = torch.nn.Linear(784, hidden_layer_size, bias = True)
linear2 = torch.nn.Linear(hidden_layer_size, 10, bias = True)
relu = torch.nn.ReLU()
model = torch.nn.Sequential(linear1, relu, linear2)The 512 hidden layer size was the first power of two, giving good results. The 784 comes from the input size, which is 28×28. So, the hidden layer is a list of 512 28×28 matrices. I took every matrix and compressed it with JPEG to only 20% quality, where I lost a lot of information, as can be seen here.
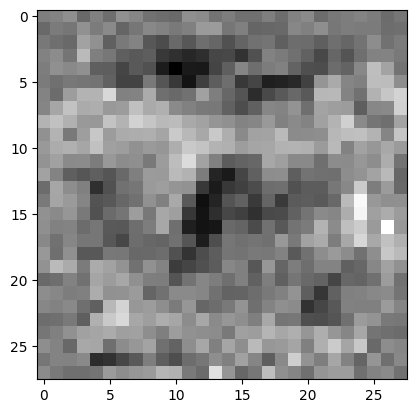
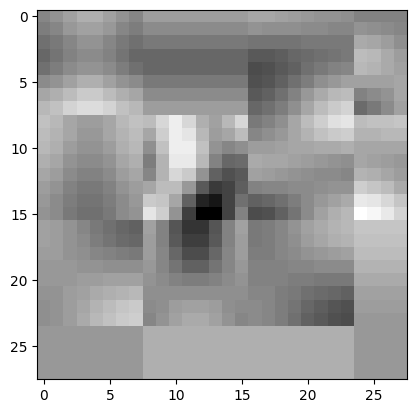
The test accuracy only dropped from 97% to 96% which is astounding for the reduction of resolution in the latent space.
What have we learned? And some educated guesses.
The weights in a CNN are very redundant. We can reduce the dimensionality substantially by some naive algorithm like JPEG. But to do a forward propagation in the network, I need the matrix version of the JPEG which does not save any memory. It could be used to ship weights over a low bandwidth network like the internet. However, we can pose some educated guesses:
- Choosing a different basis for the weights, like Fourier-basis than just an independent weight at every place, might enable to produce huge networks with a limited number of weights.
- This method might also work in deep neural networks.
- Creating a differentiable method that produces significant complexity with little parameters might increase the computational capabilities of given hardware.
Leave a Reply